Picture 1
Description
A novel processor architecture based on dataflow architecture techniques and with support for SMT is proposed. Analysis indicates that instructions are normally not dependent on all registers in register file. Since there are many hazards due to simultaneous access to several registers an architecture based on systolical array computers was evaluated. The idea is to provide less register visibility, from a functional unit perspective.A functional unit, FU, can perform any logical or arithmetic integer operation, for example AND, OR, SHL, MOV, or MUL. If MUL is too slow this can cause some problems so it will not be included in the first design. Every FU does its own simple instrucion decoding.
FUs are connected locally with an optimized connection topology so buses can be short. Registers are distributed, so that each FU includes only one register, into which it can write. Also the data from its neighbours could be read. Neighbours of FU x are all FUs, that is FU x connected to.As we normally need more registers than we have FUs there is a problem. This problem was solved using local registers in a technique that will be described later. There are also some great benefits incorporating such local processing. Local processing eliminates pipelining and all pipelineing hazards are eliminated. Unfortunetly we may need pipelineing just for instruction loading, if data and instruction share the same bus.
The matrix size is to be selected based on an analysis of real code. In our study of instruction appearance frequencies, aproximately 10% of instructions are memory store, 20% memory load, and 70% other types. Based on this analysis we conclude that in average conditions 3 to 4 FUs on the same bus could efficiently access memory assuming appropriate compiler optimization.
Besides local instruction decoding is performed by each FU, we have also global decoding unit, which decodes general instructions, and passes data into FUs. General instructions include jumps and other control type and some special instructions.
Since there is limited parallism in most current programs, it is expected that larger vertical matrix sizes would not yield more speed.
A more detailed proposal is available in Adobe PDF document or in Postscript document.
Simulation Results
First we did some simulations to analyse average desktop computer programs.
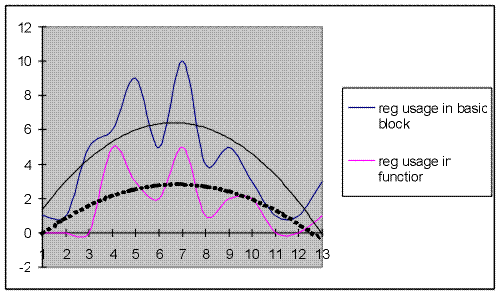
In the figure above we can see average register usage per function and per basic block. This analysis was based on the Dhrystone program. Based on this result the number of registers needed to prevent unnecessary register spilling can be estimiated.
If an algorithm similar to one described in draft proposal is used, we get following results. Of course the results may vary for different versions of optimizators and test programs:
Global parallelity (theoretical max. with normal BB-BB dependencies): 3.2-3.7 Global parallelity achieved in last or2k optimizator: 2.4-2.7
Further increases in the matrix size does not offer more power for such desktop applications. However this design could mean real speed up for DSPs, and other applications having higher instruction parallelism.
Since current desktop CISC processors do not achieve IPC greater than 2, the results are pretty good. Also ASIC and FPGA or2k implementation should have probably higher clock speeds than normal processor cores (CISC, RISC).
Optimizator status:
Project Status:
Maintainer:
Working team:
Mailing-list: